•“Deep learning is a subset of machine learning, which is essentially a neural network with three or more layers. These neural networks attempt to simulate the behavior of the human brain—albeit far from matching its ability—allowing it to “learn” from large amounts of data.”
Deep learning, including LSTM (Long Short-Term Memory), is typically trained using large datasets and an iterative optimization process. The training process involves several steps. Firstly, the input data is preprocessed, which may include normalization, feature scaling, or data augmentation techniques. Then, the data is split into training and validation sets to evaluate the model’s performance during training. Next, the model architecture is defined, specifying the number and type of layers, activation functions, and other hyperparameters. Python libraries such as TensorFlow, Keras, or PyTorch are commonly used to build and train deep learning models. These libraries provide high-level abstractions, making it easier to design, train, and evaluate neural networks.
Model Creation
During training, the model weights are initialized, and the forward and backward propagation algorithms are applied. The forward pass involves passing input data through the layers of the neural network, while the backward pass calculates the gradients of the loss function with respect to the weights, using techniques like backpropagation. Optimization algorithms, such as stochastic gradient descent (SGD), Adam, or RMSprop, are employed to update the model’s weights iteratively, aiming to minimize the loss function. The training process continues for multiple epochs, where each epoch involves going through the entire training dataset. The validation set is used to monitor the model’s performance and avoid overfitting. The process stops when the model reaches a satisfactory level of accuracy or when a stopping criterion is met.
Popular deep learning libraries in Python include TensorFlow, which provides a flexible and comprehensive framework for training deep neural networks, and its high-level API called Keras. PyTorch is another widely used library that offers dynamic computation graphs and is favored for its simplicity and ease of use. Both libraries provide built-in support for LSTM and other types of neural networks, making them suitable choices for training deep learning models in Python.
Training
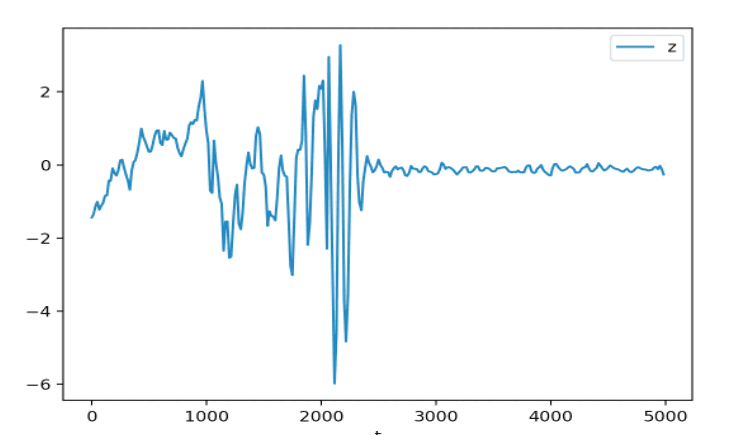
The following Code captures the information from the accelerometer and device motion.
The object “DeviceMotion: is then attached to a listener with a callback in a promise to a deviceMotionchecker to store every 250ms the information captured from the motion and submitted to a sever as a JSON object.
app.get("/gestures", function(request, response){
console.log("Gestures... ");
response.sendFile("/var/www/app.mevia.tv/accel/touch.html");
});
app.post('/json', function(request, response){
console.log("In the post Request");
console.log(request.body); // your JSON
i=0;
if (typeof args[0] == "undefined") {
DIRECTION=".";
}
else {
DIRECTION=args[0];
}
fout = DIRECTION+"/"+"data"+i+".json";
while (i<100){
fout = DIRECTION+"/data"+i+".json"
try {
if (fs.existsSync(fout)) {
i=i+1;
} else {
json_data = JSON.stringify(request.body);
fs.writeFileSync(fout, json_data);
i=101;
}
} catch(err) {
console.error(err);
}
}
response.sendStatus(200);
console.log(fout);
// response.send(request.body); // echo the result back
});
The training data is performed and stored as up.csv, down.csv, left.csv, right.csv, forward.csv and backward.csv. which are mapped to 0,1,2,3,4,5,
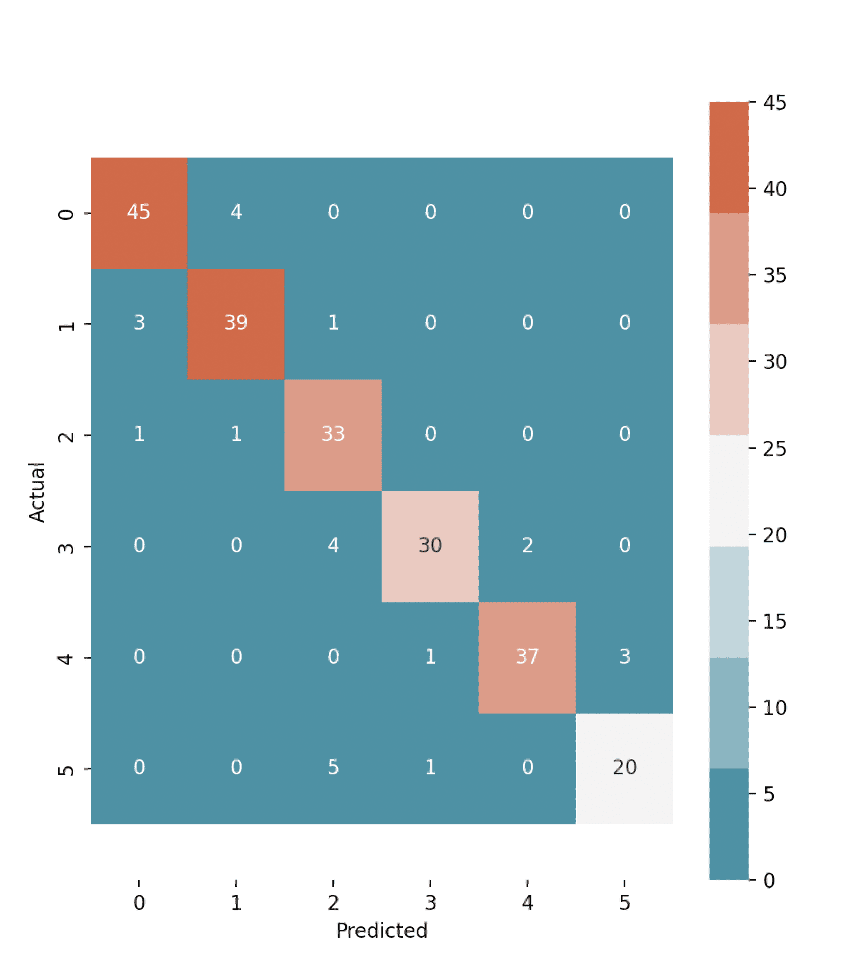
Confusion Matrix
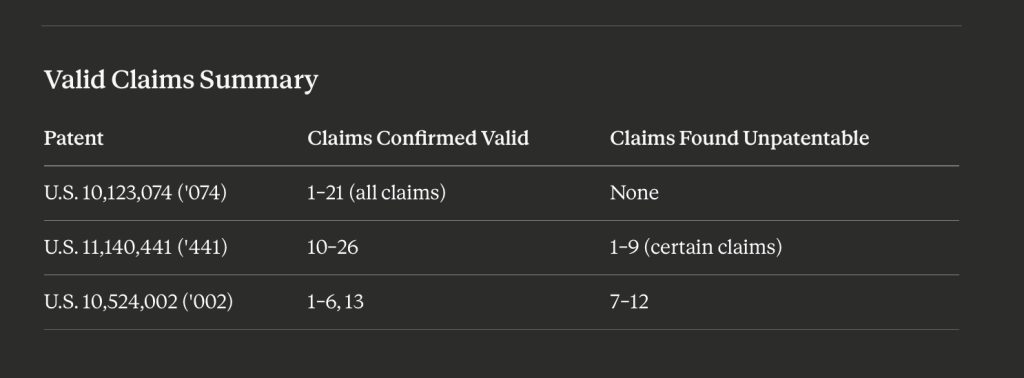
The confusion matrix is a powerful tool used in conjunction with LSTM (Long Short-Term Memory) training information to evaluate the performance and effectiveness of a model in tasks such as classification or prediction. It provides a comprehensive summary of the model’s predictions by organizing them into four categories: true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). TP represents the instances correctly classified as positive, while TN indicates the instances correctly classified as negative. FP refers to the instances that were falsely classified as positive, and FN represents the instances that were falsely classified as negative. By analyzing the confusion matrix, various performance metrics can be derived, such as accuracy, precision, recall, and F1-score, which offer valuable insights into the model’s strengths and weaknesses. This information helps researchers and practitioners refine and optimize LSTM models to achieve higher accuracy and reliability in their predictions.






{kind=link}
{kind=link}
{kind=link}