Secured coworking spaces are a need with today’s workforce. The concept of a “Next Generation” space is tailored for a future and soon to take over […]
Artificial Intelligence in 4G and 5G Systems At the Mobile World Congress 2019, I found many interesting things, first and foremost many robots, AI, and not […]
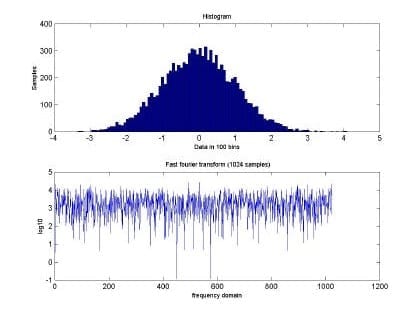
Predicting Network Traffic using Radial-basis Function Neural Networks – Fractal Behavior I found a paper about Predicting Network Traffic using RBFNN. I wrote this back in […]


{kind=link}
{kind=link}