Deep Learning with LSTM •“Deep learning is a subset of machine learning, which is essentially a neural network with three or more layers. These neural networks attempt […]
Artificial Intelligence in 4G and 5G Systems At the Mobile World Congress 2019, I found many interesting things, first and foremost many robots, AI, and not […]
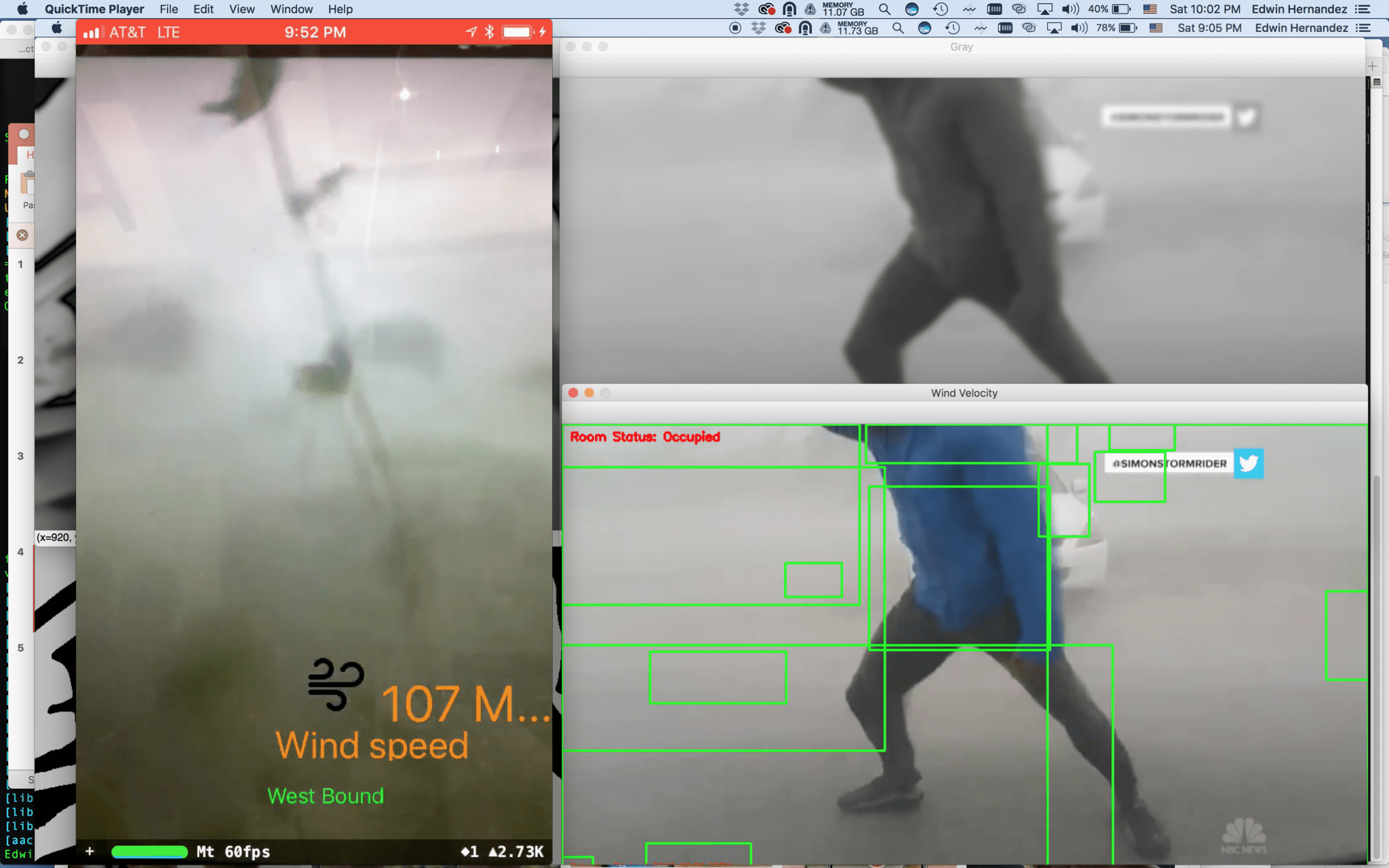
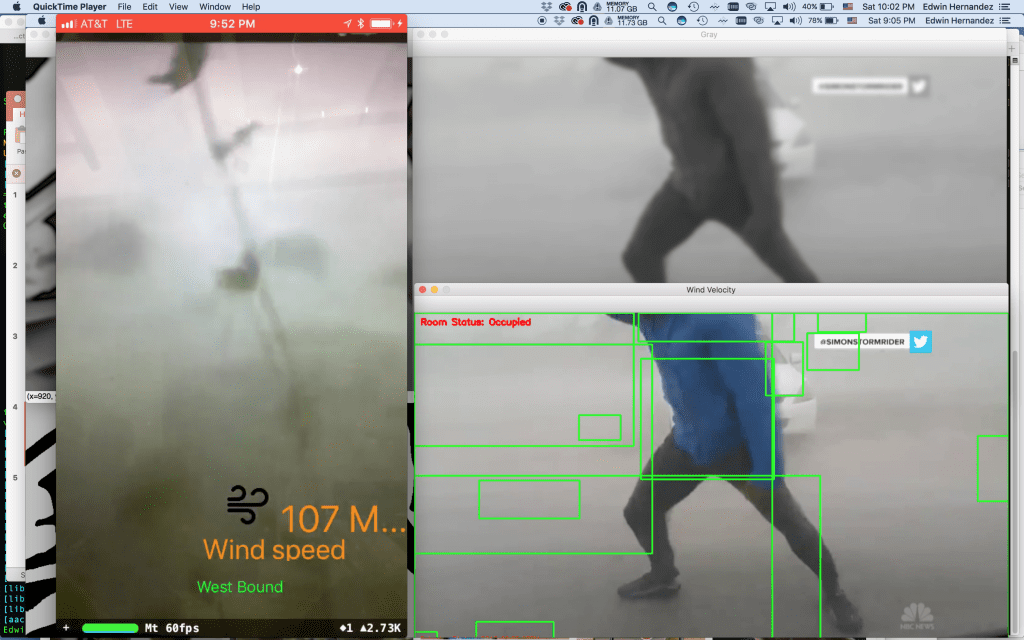
Augmented Reality Anemometer – First Update During the “Emerge Americas Hackathon 2018,” the theme was “Miami Resilience” and specially with all the hurricane events in Florida […]
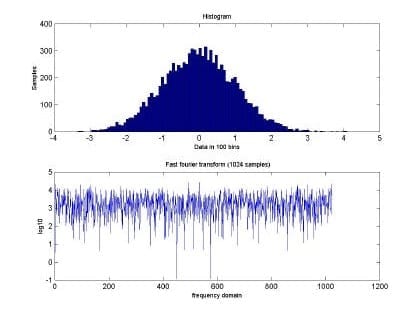
Predicting Network Traffic using Radial-basis Function Neural Networks – Fractal Behavior I found a paper about Predicting Network Traffic using RBFNN. I wrote this back in […]


{kind=link}
{kind=link}