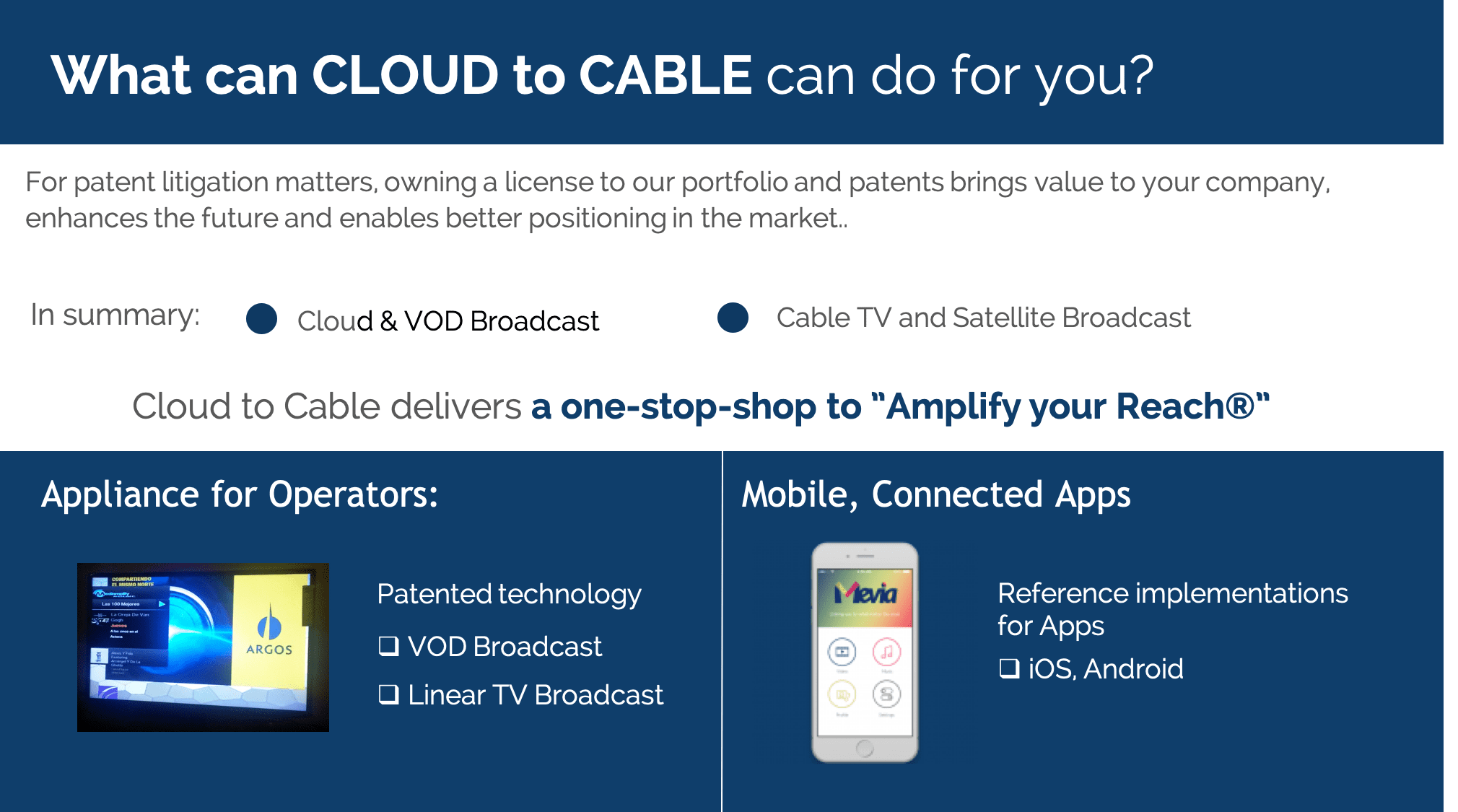
Cloud to Cable TV is the platform that makes it easy to send music channels, video channels, video on demand, and any other multimedia streaming content […]
Anvato Acquisition by Google Compared with EGLA CORP An announcement was found today regarding ANVATO, one of the OTT Platforms in the market. Slideshare brings an […]
What’s Hadoop? What’s Hadoop? Hadoop is a framework or tools that enable the partition and split of tasks across multiple server and nodes on a network. […]
Virtualization with Docker and XenServer Virtualization with Docker and XenServer has been occurring for several years . According to google search, Virtualization consists on: ” Virtualization is […]


{kind=link}
{kind=link}
{kind=link}
{kind=link}