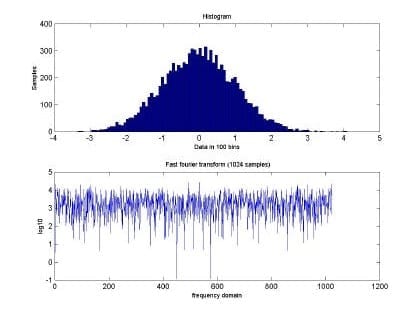
August 3, 2017Published by eglacorp on August 3, 2017Categories AI Big Data Machine Learning Neural NetworksPredicting Network Traffic using Radial-basis Function Neural NetworksPredicting Network Traffic using Radial-basis Function Neural Networks – Fractal Behavior I found a paper about Predicting Network Traffic using RBFNN. I wrote this back in […]